 Debian
Debian-France
Debian-Facile
Debian-fr.org
Forum-Debian.fr
Debian ?
Communautés
Debian
Debian-France
Debian-Facile
Debian-fr.org
Forum-Debian.fr
Debian ?
Communautés

Vous n'êtes pas identifié(e).

un segment serait déterminé par sa position de départ et sa position d'arrivée (disons « x » et « y ») correspondant aux « coordonnées » ligne / colonne du premier et du dernier caractères de la chaîne.
Avantage : c'est une information prenant peu de place à stocker
Inconvénient : le texte serait nécessairement en lecture seule, pour ne pas modifier x et y
un segment serait enregistré entièrement. On utiliserait les expressions régulières pour retrouver le segment dans le texte (et ainsi le colorer)
Avantage : le texte non codé pourrait être modifiable
Inconvénient : ça me paraît plus lourd à la fois en termes de traitement (expressions régulières) et de stockage (segments entiers et non plus seulement des coordonnées)
Voici donc l'état de mes réflexions balbutiantes et non-expertes. Qu'en pensez-vous ? Toute aide/suggestion/remarque est plus que bienvenue. ![]()
Je suis aussi sur Twitter et nouvellement sur Diaspora*
Mon blog de geekeries : HAL-9000
(J'applique la règle de proximité)
Hors ligne

Leonlemouton
°(")°
Hors ligne
Je suis aussi sur Twitter et nouvellement sur Diaspora*
Mon blog de geekeries : HAL-9000
(J'applique la règle de proximité)
Hors ligne
Leonlemouton
°(")°
Hors ligne
Je suis aussi sur Twitter et nouvellement sur Diaspora*
Mon blog de geekeries : HAL-9000
(J'applique la règle de proximité)
Hors ligne
ville: Paris
revenu: 4500
ville: <ville>Paris</ville>
revenu: <revenu>4500</revenu>
Je ne sais pas quels sont les quantités de données que tu envisages de traitées. Je ne pense pas que la taille pose de pb mais la difficulté est de structurer tes données pour les rendre exploitable par la suite.
De tous les cas j'envisagerai de garder l'intégralité de tes interviews afin garder le contexte en complément des données.
la deuxième partie correspond à des requêtes sur tes données, et c'est pour moi de la base de données.
L'objectif ? Ils peuvent être multiples : le premier est de récupérer l'ensemble des segments correspondant à un code, sur l'ensemble des entretiens (par exemple, regrouper tous les extraits évoquant « installation à la ville ») ; mais on peut en imaginer d'autres : croiser des codes et des méta-informations (par exemple, créer des variables « sexe » et « catégorie-socio-pro » qui constituent des méta-données de l'entretien, et croiser ces variables avec les codes), et d'autres choses encore.
Je comprends pas ce que tu entends pas meta données. Pourrais tu donner un exemple ?
Je comprends pas ce que tu entends pas meta données. Pourrais tu donner un exemple ?
Par méta-données j'entends toute donnée qui n'est pas l'entretien lui-même. L'entretien (retranscrit, évidemment) représente les données « de base ». J'appelle méta-données toute donnée permettant de caractériser l'entretien. Ces méta-données sont dépendantes de la recherche / du chercheur et de sa problématique (même s'il y a de fortes chances que des méta-données comme le sexe, l'âge, la profession, intéressent souvent le chercheur… en gros, des variables socio-démographiques « classiques »).
À titre d'exemple, toujours si j'enquête sur les étudiants, je pourrais créer la méta-donnée « profession des parents » (qui ne serait pas nécessairement une donnée figurant en claire dans l'entretien : j'aurais pu demander à mon enquêté la profession de ses parents hors micro, par exemple). Une fois les méta-données renseignées, le « croisement » entre celles-ci et les codes permet, par exemple, de se rendre compte que tels enfants issus de tel milieu social n'évoque pas tel sujet (ça, c'est facilement chiffrable : tel code est présent/absent de tel entretien, ou encore, tel code représente x% de tel entretien), ou l'évoque d'une façon particulière (ça, c'est l'interprétation du chercheur, le logiciel ne peut rien faire à ce niveau. Son seul intérêt et d'aider à la comparaison en réunissant les uns sous les autres les morceaux codés à comparer).
Je ne sais pas si je suis assez clair ![]()
Dernière modification par Lunatic (20-04-2014 22:27:10)
Je suis aussi sur Twitter et nouvellement sur Diaspora*
Mon blog de geekeries : HAL-9000
(J'applique la règle de proximité)
Hors ligne

Dernière modification par GuilOooo (21-04-2014 09:56:14)
Hors ligne
Ton css permet de visualiser comme tu entends ton texte. Tu peux envisager de visualiser ton texte en mettant en évidence tes différents codes par un système de couleur (ce système à ces limites). Mais tu évidement lire ton texte sous sa forme d'origine en supprimant dans ton CSS la balise des différents tags. Tu peux envisager de n'afficher que les éléments codé et masqué le reste de l'interview.
Dans ce cas, cela t'évite de dupliquer tes interviews, et de pouvoir ajouter facilement des commentaires visible ou non.
L'avantage est de pouvoir rester sur un système très simple et de coller sur un standard.
Concernant la notion de méta données, est ce que je peux simplifier par:
- code: variable présente dans l'interview. Les codes sont spécifiques à une seule étude.
- meta données: variable présente ou non dans l'interview (dans ce cas c'est l'intervieweur qui ajoute cette info) mais qui relève de notion plus générale et est généralement présente dans l'ensemble des études
Pour moi, il s'agit de notions assez proches mais qui nécessite de pouvoir les distinguer. <code_filière> <meta_age>
Je pense avoir une idée assez précise de ce que tu recherche pour ce qui est du "codage" des interviews.. Je n'ai pas cherché à regarder comment fonctionnait ce genre d'outil pour ne pas être orienté et répondre à tes besoins.
Avant d'aller plus loin, j'attends ton avis et tes critiques. Il s'agit de ton projet, mes suggestions ne sont là que pour t'aider et te guider vers des choix qui me paraissent plus judicieux mais pas nécessairement la meilleure solution.
qui n'est pas du HTML valide.
D'ailleurs, <tag1> n'est pas du HTML valide non-plus, on devrait écrire <span class="tag1">… Donc autant spécifier son propre format basé sur du XML.
Hors ligne
C'est redondant et pas génial.
Mais je sais aussi faire une usine à gaz
Du coup ça permettrait d'être relativement transparent à la lecture. Je sais pas si mon idée est claire.
A voir si le cas peut réellement se présenter (c'est fort probable), si oui il faudrait voir comment contourner ce pb.
Effectivement, j'avais dans l'esprit le xml mais il est plus facile de parler du HTML.
Pour résumer, tu voudrais pouvoir surligner des parties de texte en donnant une légende qui associe des significations aux couleurs de surlignage ? Dans ce cas, pourquoi ne pas utiliser LibreOffice Writer ? C'est sans doute un peu naïf de ma part, mais s'il s'agit simplement de mise en forme, il devrait savoir le faire. Au pire, une petite extension pour LOWriter pourrait rajouter les fonctionnalités dont tu as besoin (je crois qu'il est possible d'en écrire en Python, je ne pourrais pas le promettre).
Le type de logiciel que je présente est effectivement ? en tout cas, pour sa fonctionnalité de base ? une sorte du « super-surligneur ». Je n'avais pas pensé à l'utilisation de LibreOffice mais si j'exploite cette piste, il est clair qu'il faut une extension, pour les raisons suivantes :
- on ne peut pas se contenter de surligner avec des couleurs. Le nombre de codes peut être grand, le codeur ne peut pas retenir « telle couleur = tel code ». Il lui faut donc interagir directement sur des codes, pas sur des couleurs.
- sans extension, il n'y a à ma connaissance aucun moyen de lancer une fonctionnalité « sors moi tout ce qui est codé par tel code » (autrement dit « sors moi tout ce qui est surligné en telle couleur »). Surtout, il faut bien imaginer que l’intérêt de cette fonctionnalité est de pouvoir agir sur plusieurs fichiers distincts, donc plusieurs textes (= plusieurs entretiens, de plusieurs personnes) pour réunir en 1 même document les passages codés d'un même code.
- les logiciels de QDA présentent une fenêtre listant l'ensemble des documents textes (= des entretiens) traités. En un clic on passe de l'un à l'autre. Je ne sais pas si avec LibreOffice on peut faire ça facilement (ça s'apparente peu ou prou à la « gestion de projets » dans des éditeurs de textes orientés programmation, ou dans des IDE).
Si tu as besoin de fonctions plus avancées, quelles sont-elles ?
Au niveau du codage, quelques fonctionnalités qui me semblent importantes :
- possibilité d'une structure arborescente. Tout segment de texte codé par un code enfant est automatiquement codé par le code parent. Imaginons qu'on ait les codes suivants (je reprends l'exemple de mon étude fictive sur les étudiants) :
Tout segment codé « déménagement jugé libérateur » serait codé de facto « relation à la famille ».
- une fonctionnalité présente dans Weft-QDA et qui est très pratique est qu'on peut coder un texte déjà issu d'un codage. Je m'explique : disons qu'on analyse 5 entretiens, A, B, C, D, E. J'utilise la fonction permettant de retrouver tous les segments textuels codés « choix de la filière » sur ces 5 documents. L'ensemble de ces segments constitue une sixième document, F (évidemment, dans ce document F, chaque segment est précédé d'une chaîne de caractères rappelant son origine : A, B, C, D ou E). Bien. Ce qui est intéressant est alors de pouvoir coder F : cela permet d'atteindre un niveau de précision supplémentaire (la logique du chercheur est de se dire : « bien, maintenant que j'ai tout mes extraits évoquant le choix de la filière, rentrons dans les détails et appliquons de nouveaux codes, plus précis. Par exemple « choix de la filière contraint », « choix de la filière libre »). Je code donc F. Les nouveaux codes (les 2 que je viens de présenter, « libre » et « contraint ») doivent être retrouvables dans A, B, C, D, E.
- toujours dans la phase codage, il faut imaginer un petit outil « mémo » qui soit concrètement un texte de champ libre (un « textarea » en html) qui permette d'expliquer ce qu'on entend par tel ou tel code (dans l'optique de ne pas être perdu si on reprend le projet des mois plus tard ou si on le transmet à quelqu'un).
- dans la phase « analyse », une fois que le codage est donc terminé, il faut pouvoir imaginer lancer à peu près toutes les requêtes qu'on veut, soit uniquement sur des codes (« sors moi tout ce qui est codé par le code x et par le code y », « sors moi tout ce qui est codé par (code x et code y) ou code z » etc.) soit sur des codes et ce que j'ai appelé les méta-données (« sors moi tout ce qui est codé par le code x et qui provient des entretiens ayant telle méta-donnée », etc). Dans Weft-QDA, une fonctionnalité intéressante est qu'on obtient un tableau des résultats (c'est très pratique pour se rendre compte d'un coup d'œil que tel code est toujours ? ou jamais ? associé à tel autre code, ou tel code est toujours ? ou jamais ? associé à telle méta-donnée) :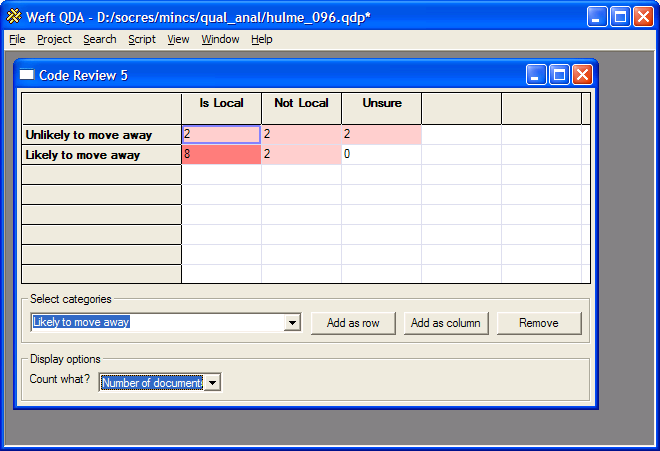
on accède alors aux segments textuels correspondants en cliquant sur la case.
Concernant ta question de départ, j'aurais tendance à stocker l'entretien en entier dans une chaîne de caractères. Les différents passages surlignés seraient ensuite représentés par les indices des bornes, i.e. des couples (indice du début, indice de fin). Inutile de s'encombrer avec les lignes/colones : le retour à la ligne n'est qu'un caractère particulier, on peut l'ignorer totalement et simplement stocker la positition brute dans la chaîne de caractères.
Effectivement, merci pour cette judicieuse remarque.
Toutefois, ce que je t'indique n'est qu'une préférence personnelle, tout fonctionnerait très bien des deux façons que tu proposes. Je pense que ton choix dépendra plutôt de la bibliothèque que tu vas utiliser pour afficher ton code à l'écran, et ce qu'elle t'impose comme format.
À ce propos, mon choix n'est pas arrêté, mais dans mes rêves de grandeur les plus fous où mon logiciel est mondialement connu dans ma fac, il faut qu'il soit facilement utilisable quelque soit la plateforme ; j'ai pensé à PySlide qui me paraît riche. Mais, je me répète, mon choix n'est pas arrêté.
Ton css permet de visualiser comme tu entends ton texte. Tu peux envisager de visualiser ton texte en mettant en évidence tes différents codes par un système de couleur (ce système à ces limites). Mais tu évidement lire ton texte sous sa forme d'origine en supprimant dans ton CSS la balise des différents tags. Tu peux envisager de n'afficher que les éléments codé et masqué le reste de l'interview.
Dans ce cas, cela t'évite de dupliquer tes interviews, et de pouvoir ajouter facilement des commentaires visible ou non.
L'avantage est de pouvoir rester sur un système très simple et de coller sur un standard.
Oui, c'est donc la deuxième grande possibilité en plus de la formule proposée par GuilOooo consistant à stocker la position début/fin du segment dans une chaîne de caractères.
Vu ce que j'ai expliqué ci-dessus (coder un document F issu de 5 entretiens A..E doit permettre de retrouver des nouveaux codes dans A..E), je me demande si le plus simple n'est pas d'employer un tel système de balises.
Concernant la notion de méta données, est ce que je peux simplifier par:
- code: variable présente dans l'interview. Les codes sont spécifiques à une seule étude.
- meta données: variable présente ou non dans l'interview (dans ce cas c'est l'intervieweur qui ajoute cette info) mais qui relève de notion plus générale et est généralement présente dans l'ensemble des études
Oui, on peut présenter les choses comme tu le fais. Le code fait nécessairement référence à un passage identifié du texte, ayant un début et une fin. La méta-donnée, pas forcément. Elle peut caractériser l'ensemble du texte/du discours (par exemple, je peux imaginer créer la méta-donnée « facilité de parole » qui me permettra de stocker l'info du type « mon interviewé était super à l'aise » ou au contraire « j'ai dû lui tirer les vers du nez »), elle peut caractériser la personne qui tient le discours (profession, âge, sexe, etc.), elle peut aussi être de n'importe quelle nature que je jugerai utile pour mon analyse (par exemple, je peux me rendre compte que certaines biographies de mes étudiants sont caractérisées par leur fluidité et d'autres pour leurs « coupures » violentes, et je pourrais alors trouver utile de créer un méta-donnée à ce propos pour ensuite effectuer des requêtes la prenant en compte).
Donc effectivement, il est indispensable de distinguer ces deux types d'informations.
Avant d'aller plus loin, j'attends ton avis et tes critiques. Il s'agit de ton projet, mes suggestions ne sont là que pour t'aider et te guider vers des choix qui me paraissent plus judicieux mais pas nécessairement la meilleure solution.
Bien sûr, et je t'en remercie encore !
Vous pardonnerez la longueur du message, j'ai essayé d'être le plus clair possible pour que vous puissiez comprendre le « cahier des charges ».
Bonne journée !
Je suis aussi sur Twitter et nouvellement sur Diaspora*
Mon blog de geekeries : HAL-9000
(J'applique la règle de proximité)
Hors ligne
Très bonne remarque concernant le chevauchement de 2 segments. Dans ce cas c'est plus compliqué. Il faudrait reformuler l'interview et c'est pas forcément pratique.
C'est surtout totalement exclu ![]() J'suis pas journaliste, je ne retouche pas mes interviews
J'suis pas journaliste, je ne retouche pas mes interviews ![]()
Je suis aussi sur Twitter et nouvellement sur Diaspora*
Mon blog de geekeries : HAL-9000
(J'applique la règle de proximité)
Hors ligne
Hors ligne

captnfab,
Association Debian-Facile, bépo.
TheDoctor: Your wish is my command… But be careful what you wish for.
Hors ligne
Je suis aussi sur Twitter et nouvellement sur Diaspora*
Mon blog de geekeries : HAL-9000
(J'applique la règle de proximité)
Hors ligne
pour une interview de synthèse
Du coup tu es capable de naviguer de ta synthèse à la source.
Concernant la capacité à ajouter une description à chacun des codes, éventuellement une couleur ne sera pas possible dans un éditeur de texte.
Je suppose qu'il faudrait être capable de garder certains commentaires et couleur pour ce qui est des meta.
L'utilisation des codes et meta données me semble important et conditionnant l'analyse. Je suppose qu'elle est chronophage et doit être rapide et intuitive.
Je verrai un ecran présentant l'interview ainsi que 2 barres d'outil pour les codes et les méta données. L'idée est de retrouver les codes existants dans l'étude et ajouter le commentaire et accessoirement de gérer la couleur du segment associé.
Je pense que ton projet ne pose pas trop de difficultés et devrait être réalisable.
Le fait de créer une interview "de synthèse" serait pour moi une fonctionnalité similaire mais plus évolué. La nécessité de retrouver la source me parait logique.
Je pense que F ne devrait même pas existé mais issu d'une requête. Est ce que cette interview ne comporte pas ses propres commentaires ?
Qu'entends-tu par « commentaire » ?
En effet, F n'existe pas « en soi », il est produit « à la volée » à l'issue d'une requête. Il est une compilation de morceaux d'interviews, provenant de plusieurs interviewés. Seulement, une fois qu'il est créé, il faut bien qu'il soit sauvegardé quelque part pour pouvoir facilement le retrouver et travailler dessus (en refaisant une phase de codage).
pour une interview
<etude1>
<interview19>
....<code2>lorem ipsum</code2>
</interview19>
</etude1>
pour une interview de synthèse
<etude1>
<interview19>
....<code2>lorem ipsum</code2>
</interview19>
</etude1>
<etude1>
<interview20>
....<code2>Dolor Sit amet</code2>
</interview20>
</etude1>
...
Du coup tu es capable de naviguer de ta synthèse à la source.
C'est l'idée. Après reste la question que vous évoquiez avec GuilOooo du chevauchement des balises ![]()
Concernant la capacité à ajouter une description à chacun des codes, éventuellement une couleur ne sera pas possible dans un éditeur de texte.
J'ai l'impression que PySlide permet l'utilisation de champ de texte « avancé » avec couleur et compagnie. Mais là j'avoue qu'on touche aux limites de mes connaissances (et c'est d'ailleurs bien ça que je cherche à améliorer ![]() )
)
Je suppose qu'il faudrait être capable de garder certains commentaires et couleur pour ce qui est des meta.
Les méta n'ont pas besoin de couleur. Ce ne sont pas des données visibles dans l'entretien, elles sont là pour effectuer des requêtes précises et éventuellement découvrir des corrélations.
L'utilisation des codes et meta données me semble important et conditionnant l'analyse. Je suppose qu'elle est chronophage et doit être rapide et intuitive.
Oui, surtout les codes d'ailleurs. Normalement les méta on ne les manipule pas tant que ça (je renseigne une fois pour toute ? par entretien ? l'âge, la profession, ou autre chose. Je peux en ajouter plus tard, mais théoriquement ça reste limité en nombre). Les codes par contre doivent être très facilement créables, renommables, supprimables.
Je verrai un ecran présentant l'interview ainsi que 2 barres d'outil pour les codes et les méta données. L'idée est de retrouver les codes existants dans l'étude et ajouter le commentaire et accessoirement de gérer la couleur du segment associé.
Je ne suis pas certain que les méta-données méritent d'être affichées en permanence à l'écran. Ce n'est pas le plus crucial, on peut les modifier via une fenêtre accessible depuis un menu. En revanche tu as raison pour le reste, il faut nécessairement que les codes soient toujours présents à l'écran, ainsi que la partie la plus grande, centrale, affichant le texte. Il faut également que la liste des texte importés (= des entretiens) soit présente, pour qu'en un clic je puisse passer d'un entretien à un autre. Une dernière chose qui doit être facilement accessible : la liste des requêtes déjà lancées, qu'on doit facilement retrouver, et les documents qu'elles produisent (« F », dans notre exemple).
Je pense que ton projet ne pose pas trop de difficultés et devrait être réalisable.
J'ai également l'impression qu'il n'y a rien d'insurmontables, et que je peux y aller petit à petit. La question principale demeure la technologie à employer pour coder. L'idée des balises me plaît bien, mais pose le problème du chevauchement de celles-ci. L'idée de faire contenir un entretien dans une chaîne me paraît d'une simplicité déconcertante. Les segments codés d'un même code serait bêtement une liste de listes [[a, b], [c, d]]. En revanche, un entretien, ça peut faire une 30aine de pages. Ça fait donc une chaîne super longue…
Je suis aussi sur Twitter et nouvellement sur Diaspora*
Mon blog de geekeries : HAL-9000
(J'applique la règle de proximité)
Hors ligne
ou
mais pas
après libre à toi de suivre on non les normes du xml. Une solution pour contourner ce pb peut être trouvé.
On peut éventuellement penser avoir l'interview en lecture seule. En "surlignant" par un code, on crée un nouveau fichier qui contiendra uniquement les codes.
je donne un exemple
le fichier contenant l'interview original
le fichier contenant l'interview ne comportant que les codes
Dans ce que tu as un XML bien formé. Il existe par contre des inconvénients, notamment la duplication d'une partie de l'interview.
Concernant la taille des interviews, il ne faut pas s'inquiéter mais s'il s'agit uniquement de chaines de texte la taille est plus que limité compte tenu des capacités actuelles.
Tu peux tester en enregistrant une interview dans un fichier texte. En regardant la taille c'est pas grand chose alors une fois compressé c'est plus qu'acceptable.
J'espère te convaincre sur l'utilisation du XML car c'est simple et pratique. En plus j'avais pas pensé aux divers outils qui existent déjà et que tu pourrais utiliser. Cela te permettra de te concentrer sur l'interface et des fonctions qui te sont utiles.
on aurait ça :
Ça évite la duplication, mais c'est peut-être plus chiant à traiter ensuite ?
Je suis aussi sur Twitter et nouvellement sur Diaspora*
Mon blog de geekeries : HAL-9000
(J'applique la règle de proximité)
Hors ligne
Mais que ce soit avec ce dernier codage ou avec celui que tu proposais, comment gères-tu les requêtes de récupération des phrases de type «tag2» ?
Parce que là, tu risques de te retrouver avec deux phrases : « Dolor » et « Sit amet », découpés un peu arbitrairement.
C'est là que la version par «positions de début et de fin» est bien moins douloureuse, tu peux fusionner les segments plus facilement.
Autre possibilité, tenter un découpage «par phrase» ou «par ponctuation». Dans ce cas, ton texte est segmenté automatiquement et tu indiques juste quels tags appliquer à quels segments.
Exemple : segment 1 : entre les deux premières ponctuations, segment 2 : entre la seconde et la troisième.
Segments de tag1 : 1,2
Segments du tag2 : 1
captnfab,
Association Debian-Facile, bépo.
TheDoctor: Your wish is my command… But be careful what you wish for.
Hors ligne
Je suis aussi sur Twitter et nouvellement sur Diaspora*
Mon blog de geekeries : HAL-9000
(J'applique la règle de proximité)
Hors ligne
captnfab,
Association Debian-Facile, bépo.
TheDoctor: Your wish is my command… But be careful what you wish for.
Hors ligne
Je doute que ce choix soit viable et pose trop de pb
<tag 1 et 2> serait en fait <tag3>, du coup il faudrait faire une fonction pour faire le lien avec <tag1> et <tag2> ensuite il faudrait concaténer. On va créer des codes "systèmes" et il faudrait les différencier des codes que tu utilises.
Là ou j'ai du mal avec l'idée de coordonnées, c'est si on doit modifier l'interview pour ajouter de la poncuation, coquille ou autre. Du coup pas évident de mettre à jour. Chaque choix aura nécessairement un pour et un contre. L'objectif est de pouvoir les lister et de faire le choix le plus adapté.
Après, on se rattache à des choses que l'on connait et que l'on maitrise plutôt que d'opter pour d'autres choix certainement plus pertinent mais pour lequel on est moins à l'aise.
Je suis aussi sur Twitter et nouvellement sur Diaspora*
Mon blog de geekeries : HAL-9000
(J'applique la règle de proximité)
Hors ligne